The Waveforms of Speech
A waveform is a two dimensional representation of a sound. The two dimensions in a waveform display are time and intensity. In this course (and in most of the literature) the vertical dimension is intensity and the horizontal dimension is time.
Waveforms are also known as time domain representations of sound as they are representations of changes in intensity over time.
The intensity dimension actually displays sound pressure. Sound pressure is a measure of the tiny variations in air pressure that we are able to perceive as sound. The greater the change in pressure, the louder the sound that we hear. Intensity and pressure are physical measurements of sound amplitude whilst loudness is a psychological or perceptual measurement. The variations in air pressure, relative to atmospheric pressure, are very tiny indeed, ranging from 1/5,000,000 of atmospheric pressure for the sounds we can just hear to about 1/1,000 of atmospheric pressure for very loud sounds.
Sound intensity is often quoted in deciBels (dB). The deciBels is a logarithmic scaling of sound pressure or intensity and approximates the way the ear and brain rescale sound amplitude. In the waveforms that follow, the dB scale is not used. Intensity in these waveforms is a simple linear scaling of sound pressure.
On the following pages various aspects of the speech waveform are discussed as they appear in the accompanying diagrams. All of the diagrams represent the waveforms of the speech of a single male speaker of Australian English.
Time Scales: For figures 5 to 12 the horizontal time scale is indicated by the vertical dashed lines which are 100 milliseconds (ms) or 1/10 second apart and the waveforms on these diagrams represent 800 ms (0.8 secs) of speech. For figures 1 to 4 the waveforms are 40 ms (0.04 secs) long and there are no vertical time scale markers.
Phoneme Boundaries: Approximate phoneme boundaries are represented by thick vertical lines descending from the top boundary of each graphics box.
Waveforms and Source Characteristics
There are two types of speech sound source:-
i) periodic vibration of the vocal folds resulting in voiced speech
ii) aperiodic sound produced by turbulence at some constriction in the vocal tract resulting in voiceless speech.
These two sound sources are modified by the frequency-selective (filtering) effects of different vocal tract shapes to produce the various sounds of speech. The voiced source can be filtered ("modulated") by the position of the tongue, lips and velum to produce all of the vowels as well as the various voiced consonants. Similarly the aperiodic sources can be filtered to produce various unvoiced speech sounds, but the most important influence on the sound of such speech tokens is the position of the constriction that produces the turbulence.
It is also possible for speech sounds to result from the mixture of both voiced and unvoiced sounds resulting in, for example, voiced fricatives.
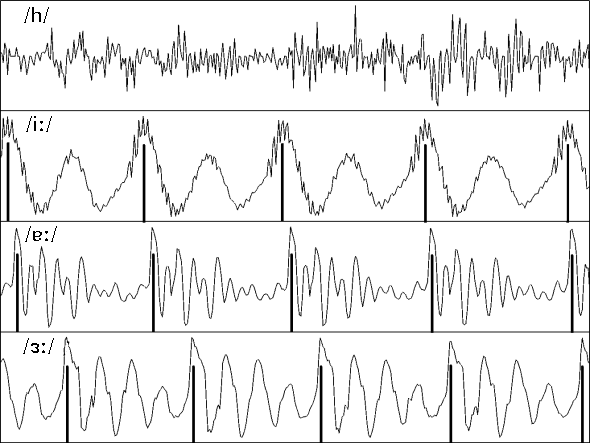
Figure 1: Close-up (40 ms) views of the waveforms of one voiceless fricative (/h/) and 3 vowel tokens.
In figure 1 one aperiodic and three periodic speech sounds are displayed for the purposes of contrasting the characteristics. The aperiodic sound /h/ when examined closely can be readily seen to be a non-repeating or random pattern. No part of the waveform pattern of this sound is repeated at regular intervals, therefore the sound is said to be aperiodic.
The three vowel sounds, on the other hand are periodic. Both the gross shape of the waveform patterns and the majority of the fine detailed features are repeated at regular intervals. In the 40 ms slice shown in these diagrams these patterns repeat themselves about four times (shown by the vertical lines). The period of these patterns is therefore about 10 ms (1/100 secs) and so the frequency of these patterns is in each case about 100 Hz. This rate of repetition of the pattern is known as the fundamental frequency (F0) of each of these speech segments. Each repetition or period of these patterns corresponds to one glottal cycle, or one cycle of vocal fold opening and closing in the larynx. An F0 of 100 Hz is a normal value for an adult male voice. An adult female voice would typically have an F0 about an octave higher (twice as high) as this, and a child's voice would have an even higher F0. The more familiar term pitch refers to the way we perceive F0. A voice with a high-sounding pitch has a high F0. The relationship between F0 and pitch is not linear and depends on the characteristics of the ear and the auditory nervous system.
The vertical lines superimposed on the diagram have been arbitrarily aligned with the highest point in each glottal cycle. They could just as reasonably have been aligned with the lowest point in each cycle or any other clearly repeating feature.
The three vowels have about the same F0 but they clearly have different patterns. The source sounds for these tokens were very similar, but the wave shapes are very dissimilar because the different tongue and lip positions have resulted in different vowel qualities. The vowel /ɜː/ waveform consists of a pattern of four peaks (each less intense than the preceding one) which are repeated every cycle. The vowel /iː/ consists of two repeating major peaks with a less intense finer detail pattern superimposed on it. It is very important to note that the fine detail also repeats quite accurately from cycle to cycle. When we look at voiced fricatives, on the other hand, we will see repeating (periodic) large peaks with non repeating (aperiodic) fine detail superimposed upon them. You must be able to distinguish between repeating and non-repeating fine detail if you are to distinguish between a periodic sound like /iː/ and a weakly mixed voiced fricative (see below).
It should be recognised that even the most purely voiced human speech sounds, such as vowels, are not perfectly periodic. Firstly, the F0 is constantly changing. This results from a combination of prosodic (esp. intonation) and segmental phenomena. Also, no pitch periods are perfectly regular. There is usually some noise generated at the glottis during normal phonation and noise can also be generated at other places in the vocal tract. Also, occasional perturbation of the vocal fold vibration can result in creaks and other imperfections in the voice. Without these variations in the voice source the speech would sound inhuman and machine-like.
Whilst some spectral information can be deduced directly from these waveforms, similar vowels (ie. adjacent on the vowel chart) cannot be distinguished. For this reason we must resort to spectral displays for explicit frequency-domain information.
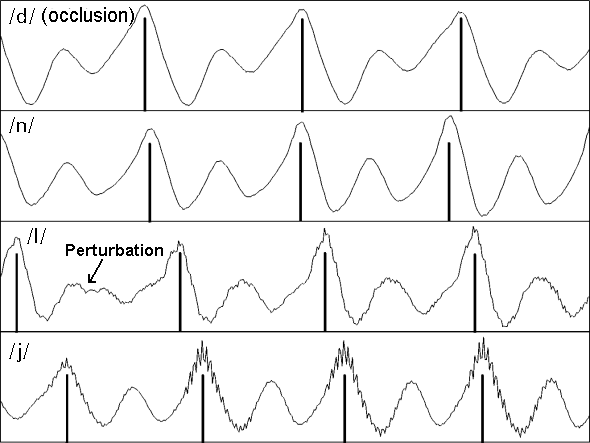
Figure 2: Close-up (40 ms) views of the waveforms of four voiced consonants.
In figure 2, four voiced consonant phonemes are presented. These four waveforms consist of almost purely voiced sources with very little visible noise. The glottal cycles or periods are indicated by the vertical lines (again, arbitrarily aligned with the highest point in each cycle. Whilst these are all periodic sounds the rapidity of many consonant sounds guarantees some change in the waveform pattern over four to five cycles.
The waveform of the voiced sound that can occur during the occlusion of a voiced stop is shown here for /d/. As the sound must radiate through the walls of the closed vocal cavity only the low frequency sounds pass relatively unhindered and so the resulting waveform consists largely of the slowly moving low frequencies. This results in a very simple waveform. Nasal sounds, such as /n/, are dominated by a strong low frequency nasal cavity peak and so the resulting waveform is also dominated by low frequencies and so is very similar to that of the occlusion voicing of /d/. It should be noted that whilst the waveforms of these two sounds are very similar visually the spectra are quite different and readily distinguished.
The approximant /l/ is also highly periodic and with the exception of a glottal perturbation (glottal creak) in the first cycle even the fine detail repeats reliably with each cycle. The approximant /j/ is quite validly called a semi-vowel. Close examination reveals a waveform almost identical to that of the /iː/ vowel in figure 1. Because /j/ changes so rapidly, however this shape only persists for a few cycles and has not been fully established until the second cycle of this section of speech.
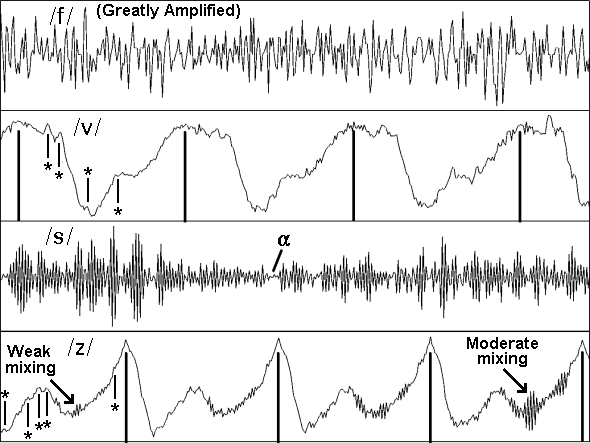
Figure 3: Close-up (40 ms) views of the waveforms of four English fricatives (/f v s z/).
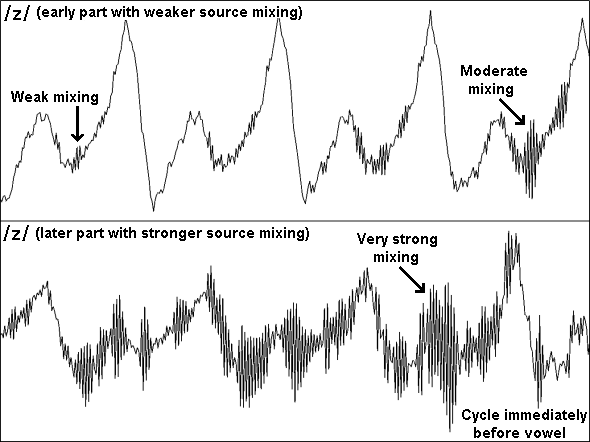
Figure 4: Close-ups of the fricative /z/ illustrating varying degrees of source mixing.
In figure 3 a pair of voiceless /f/ and voiced /v/ weak fricatives and a pair of voiceless /s/ and voiced /z/ strong fricatives are contrasted in 40 ms close-up sections of these sounds.
The /f/ waveform has been greatly amplified (relative to the /s/ waveform) so that the detailed pattern can be clearly seen. The most intense features of the /f/ waveform are really only as intense as the weakest features of the /s/ waveform (the section indicated by the symbol "![]() "). Both of the voiceless fricatives have a random waveform pattern as would be expected for aperiodic or voiceless sounds. The main difference between them, at least as far a can be discerned from a waveform, is the difference in their intensities. Note, however, that there are considerable spectral differences between them and they can be readily identified from their spectra or spectrograms.
"). Both of the voiceless fricatives have a random waveform pattern as would be expected for aperiodic or voiceless sounds. The main difference between them, at least as far a can be discerned from a waveform, is the difference in their intensities. Note, however, that there are considerable spectral differences between them and they can be readily identified from their spectra or spectrograms.
The two voiced fricatives are examples of mixed periodic/aperiodic speech sounds. Generally the periodic or voiced source is more intense than the aperiodic source and so the voiced components dominate the shape of the waveforms of these consonants. An examination of both the /v/ and the /z/ waveforms will reveal that the pattern of the large peaks is quite periodic. The pattern of the fine detail is, on the other hand, a mixture of periodic or repeating features and aperiodic or non-repeating features. The repeating minor components of each of these waveforms are indicated with a short vertical bar and the symbol "*". Superimposed over these features and the major peaks are many tiny irregular or non-repeating peaks.
The aperiodic detail for /v/ is only just discernable as this is effectively the superimposition of a weak fricative over the much stronger voiced wave. Such a sound can be said to be weakly mixed. Nevertheless the non-repetition of much of the fine detail can be seen.
For /z/ the amount of aperiodic fine detail varies considerably over the time-course of the fricative. The strength of the aperiodic sound changes from a relatively low intensity near the beginning of this fricative to a relatively high intensity at the end of the fricative near the onset of the vowel. Figure 4 illustrates the varying source characteristics for /z/ near the beginning and at the end of the same /z/ utterance. As the intensity of the aperiodic source increases relative to the voiced source the level of mixing gradually changes from weakly mixed to strongly mixed. By the last couple of periods the intensity of the aperiodic source has become so great that it has begun to dominate some of the larger periodic peaks.
For the purposes of this course you will be expected to be able to distinguish between pure voiced, pure voiceless, weakly mixed and strongly mixed speech sounds. You must be able to distinguish between periodic and aperiodic fine detail in a waveform.
Identification of Speech Waveforms
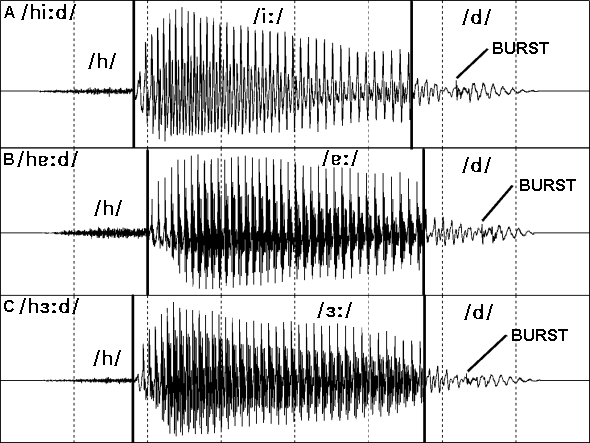
Figure 5: Three long vowels in an /h_d/ context.
The diagrams in figure 5 compare three syllables which contrast long Australian English vowels in what is known as the /h_d/ context. The vowels in these three words contrast in an identical environment for the same male speaker of Australian English. The differences between these three waveforms is therefore mainly due to the differences between the waveforms of these three vowels.
As you can see, the difference is very subtle. If you look closely you can see that the /iː/ vowel is reasonably clearly differentiated from the other two by its wave shape. The vowels /ɜː/ and /ɐː/ are very difficult to separate visually by their wave shapes. If these two waveforms are stretched out horizontally the differences become a bit clearer but even then it is not possible to separate them reliably. Waveforms can tell you that you are looking at a vowel, but they can't reliably tell you which vowel.
The vowels in these waveforms all have regularly repeating, or periodic, voiced patterns. The intensity of the vowels rises rapidly at the start, reaches a peak by about ¼ of the way through the vowel and then gradually drops. As the vowel reaches the start of the stop the intensity drops fairly rapidly. I like to compare this pattern to the pattern of a fish skeleton (the "dead fish" pattern).
You can see that the initial /h/ consonant has a much lower intensity than the vowel and it does not have any regularity in its pattern. /h/ is therefore a weak, aperiodic or voiceless consonant. The final /d/ on the other hand has a more complex waveform. It is much lower in intensity than the vowel but is nevertheless louder than the /h/. The waveform is mostly regularly repeating, or periodic. This periodic pattern is a much simpler pattern than that of the vowel as it is mainly dominated by low frequencies whilst the vowels consist of a mixture of low, medium and high frequencies. The periodic pattern of the /d/ is interrupted by an apparently weak burst (which is actually more audible than it would seem from these waveforms, for reasons which will become a little clearer when we look at the spectrograms of these sounds later).
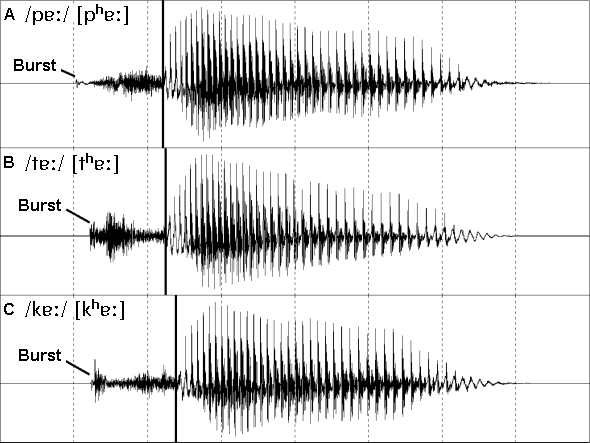
Figure 6: Three English voiceless oral stops in CV context.
The three syllables in figure 6 contrast the three voiceless oral stops of English in a "CV" (consonant + vowel) context where the vowel is always /ɐː/. The only major differences between the three waveforms are therefore the three initial voiceless stops. The irregularity or aperiodicity of the stop waveforms clearly contrasts with the regularity or periodicity of the vowel waveforms that follow.
There are some clear differences between the three stop consonant waveforms. All three stops commence with a burst. The burst occurs when a build up of air pressure is suddenly released when the two lips, tongue tip and alveolar ridge, or tongue body and soft palate closures are released. This results in a rapid flow of turbulent air which is audible and which we call the stop burst. All released stops have bursts, but not all bursts are of equal intensity and some stop bursts may not even be audible. The bursts in the /d/ of the /h_d/ syllables in figure 5 are not as strong as the burst of their voiceless counterpart /t/ shown on this page. Also, the intensity of the voiceless stop bursts varies greatly.
The bursts are very short (about 1-5 ms) and are followed by about 100 ms of aspiration (or fricative-like voiceless sound). The aspiration is all of the aperiodic waveform from immediately after the burst until the start (onset) of voicing which indicates the start of the vowel.
The burst of the voiceless alveolar stop /t/ is both quite intense and also very sudden. We move in less than a millisecond (ms) from zero intensity (no sound) to the voiceless burst and aspiration of the /t/. The tongue tip is very agile (and has a low inertia) and so it can be controlled very accurately to make very rapid articulatory manoeuvres. This results in a sharper more rapid burst than occurs for the more slowly moving lips and tongue body.
The burst of the voiceless bilabial stop /p/ is much weaker, and would be very difficult to see if the word had been recorded in a noisy room rather than a sound treated studio. The burst is not very loud and the intensity increases gradually over the course of the stop's aspiration. If we were not able to see the tiny burst then this waveform would have looked very much like a voiceless fricative (see below). When we examine the spectrogram of this sound later we will see how the frequency pattern of this stop makes the burst more audible than would appear to be the case from this waveform.
The burst of the voiceless velar stop /k/ appears to be rather complex with a weak initial burst followed about 5-10 ms later with what appears to be a stronger burst. This may be due to asymmetrical release of the tongue body from its contact with the soft palate. Perhaps some small part of the tongue's contact was lost 5-10 ms before the main body of the tongue released its contact.
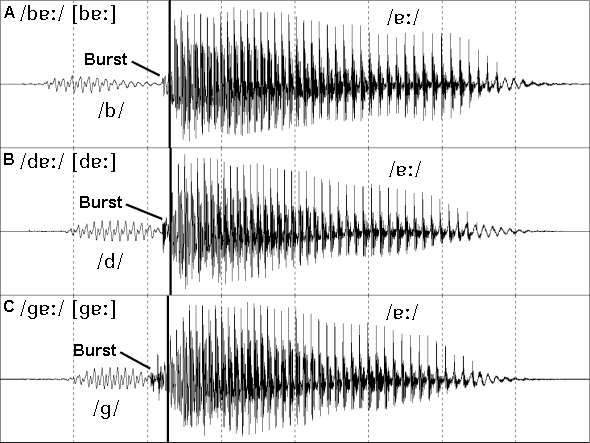
Figure 7: Three English voiced oral stops in CV context.
The three syllables in figure 7, one word and two nonsense syllables (1), contrast the three voiced oral stops of English in an identical environment.
The three stops in these three tokens are the pre-voiced allophones [b d ɡ] of the English voiced stops. These three allophones are said to have a negative Voice Onset Time (VOT) as the start of voicing precedes the stop burst. The other major allophones in this CV context are the voiceless unaspirated allophones [p t k] which have zero VOT (the onset of voicing occurs approximately simultaneously with the burst), and which in this context would be heard by English speakers as voiced stops. In a CV context the major allophones of the voiceless stop phonemes of English are [pʰ tʰ kʰ] which were displayed in figure 6 and which have positive VOT (the onset of voicing occurs significantly after the stop burst).
All three stops in figure 7 have 100-150 ms of voicing displayed before the burst that occurs at the stop release. This sound radiates through the tissue of the vocal tract as the tract is completely closed during this time. Only low frequencies are radiated through the tissues and this results in a simple waveform pattern preceding the burst.
The bursts occur immediately before the onset of the vowel. They differ from each other with respect to their intensity and duration. As with the voiceless stops, the bilabial /b/ has the weakest burst, the alveolar /d/ has the clearest burst and the velar /ɡ/ has a complex and relatively long burst. Without these bursts it would be difficult to distinguish these sounds visually from other voiced consonants with weak low frequency voicing (eg. voiced fricatives and nasal consonants). The burst is an essential visual cue in the present case and is also an essential auditory cue during the normal perception of voiced stops.
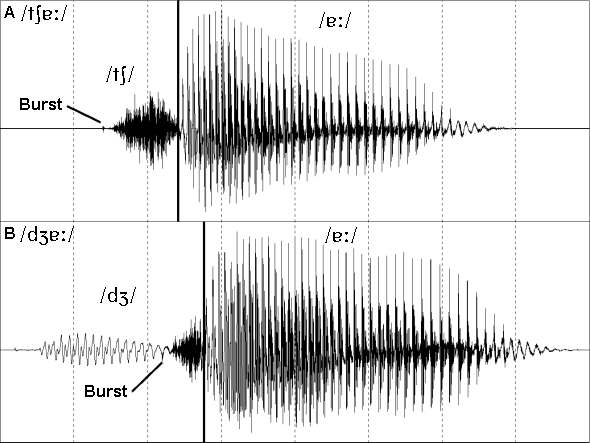
Figure 8: The two English affricates in CV context.
The two affricate waveforms displayed in figure 8 illustrate the mixture of stop and fricative features that characterise the affricates.
The voiceless affricate /tʃ/ has a weak burst followed by a very strong aspiration before the onset of voicing. The aspiration increases in intensity at a much greater rate than for the voiceless fricatives (see below). This more rapid increase in intensity also helps to reinforce the perception of the stop characteristics of this affricate. You will also notice, if you compare /tʃ/ with the /f/ or /s/ waveforms (below), that the aspiration phase of a voiceless affricate is much shorter than that of a voiceless fricative in the same context. Since the aspiration of this affricate is about the same duration as the aspiration of the three voiceless stops (above) it would be very difficult to distinguish between them on the basis of the appearance of their waveforms.
The voiced affricate /dʒ/ shares the characteristics of voiced stops and fricatives. The burst in this waveform is barely discernable and appears to actually occur simultaneously with the beginning of the last voicing cycle before the start of the aspiration phase. Without this burst, this voiced affricate would look rather similar to the waveform of the voiced fricative /z/ shown below. In both cases a voiced pattern dominates for most of the phoneme only being replaced by strong frication (aspiration) nearer to the vowel. Notice how strong and how long the aspiration of /dʒ/ is in comparison to the relative lack of aspiration in the voiced stops (but note that /ɡ/ has almost as much aspiration as /dʒ/).
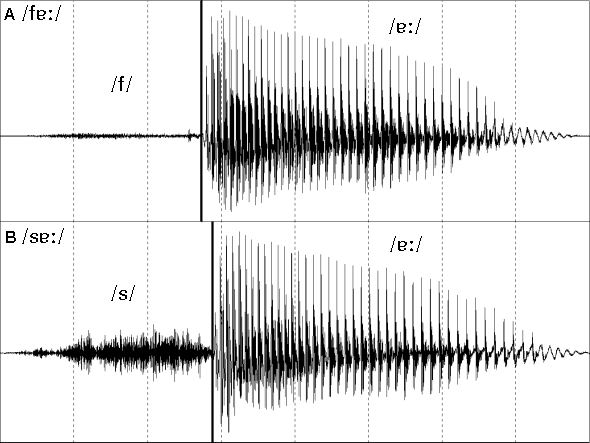
Figure 9: Waveforms of two of the English voiceless fricatives in CV context.
If you look closely at the two voiceless fricatives in figure 9 you will see that they have a completely irregular pattern. These sounds are aperiodic, which means that they don't consist of periodically repeating patterns as occurs in voiced sounds. All voiceless speech sounds are aperiodic.
The fricative aspiration in these two examples is very long, 250 to 300 ms, compared to the aspiration of the voiceless stops and affricate. Also the onset of these sounds occurs gradually. That is, they increase in intensity very slowly in contrast to the pattern in stop sounds.
Another obvious feature of these two waveforms is the distinction between the weak fricatives and the strong (sibilant, strident or grooved) fricatives. The weak voiceless fricatives in English are /f θ h/ and their voiced counterparts are /v ð/. The strong or sibilant voiceless fricatives in English are /s ʃ/ and their voiced counterparts are /z ʒ/. The sibilant fricatives are produced by turbulence through a groove in the tip of the tongue which is in contact with the alveolar ridge. The sibilant fricatives have a much greater intensity than the weak fricatives.
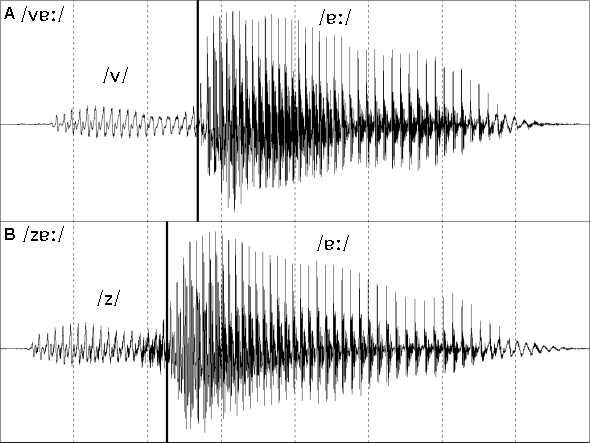
Figure 10: Waveforms of two of the voiced fricatives of English in CV context.
Figure 10 displays the waveforms of two of the four voiced fricatives of English. The voiced fricatives of English are /v ð z ʒ/. Note that there is not a voiced counterpart of /h/ in English but that all of the other fricative places of articulation have both voiced and voiceless phonemes.
Some voiced fricatives are not especially easy to recognise as voiced fricatives from their waveforms. This is especially true for the voiced weak fricatives /v ð/. The voiced weak fricatives are characterised by a medium intensity voiced waveform with only a very weak voiceless component mixed with it. The voiced component, being more intense, visually overwhelms the voiceless component of the fricative and so it is often difficult to discern the mixture of source characteristics. In the case of the /v/ waveform in figure 10, it is just possible (if you look VERY closely) to discern very slight aperiodicity superimposed over the much stronger voiced pattern of the last 4-5 glottal cycles before the start of the vowel. Note that the pattern of the /v/ is much simpler and less intense than that of the following vowel. You can detect the start of the vowel by looking for a change to a more complex periodic pattern and also a relatively sudden increase in intensity.
For the voiced strong (sibilant) fricatives /z ʒ/ the mixture is usually much clearer, especially in the last part of the fricative, just before the onset of the vowel. In the /z/ spectrum, above, the first 150 ms of the fricative shows only a weak mix of aperiodic sound with the more dominant periodic sound. This changes dramatically for the last 50 ms where the mixing becomes strong with about equal periodicity and aperiodicity. (see above for a more detailed discussion on source mixing).
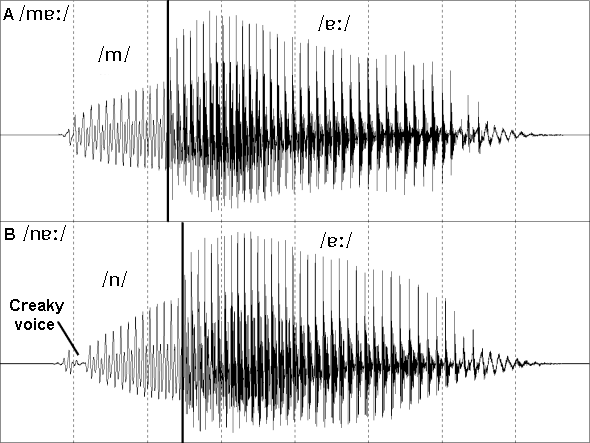
Figure 11: Waveforms of two of the nasal consonants of English in CV context.
There are three nasal stop consonants in English /m n ŋ/. Only /m/ and /n/ can occur in a CV context in English and so these sounds have been selected for display in figure 11. If you look closely you will see that the nasal consonants have a much simpler waveform pattern than the vowels. This is because the nasal articulations favour low frequency spectral components and low frequency waves vary more slowly than high frequency waves.
You can readily see where the consonant ends and the vowel starts by looking for two changes. The simplest change to see is the sudden increase in intensity that occurs as the oral cavity is opened at the start of the vowel. The open oral cavity allows more power or intensity to be transmitted from the larynx to the outside world. The other change that occurs is the change in pattern from the simple nasal consonant pattern (dominated by low frequencies) to the more complex vowel pattern (with a more even mixture of low and higher frequencies).
Another characteristic of this class of speech sounds is the general lack of aperiodicity, or aspiration, in the waveform and the absence of the bursts characteristic of the stops and affricates. If aperiodicity is very evident in the waveform it is likely to be characteristic of a pathological vocal condition such as an excessively breathy voice. The slight interruption in the waveform near the beginning of the /n/ is probably due to a slight creak in the voice. Slight and occasional creakiness in the voice is perfectly normal and only becomes pathological when it occurs continuously or for an abnormally large proportion of a person's speech.
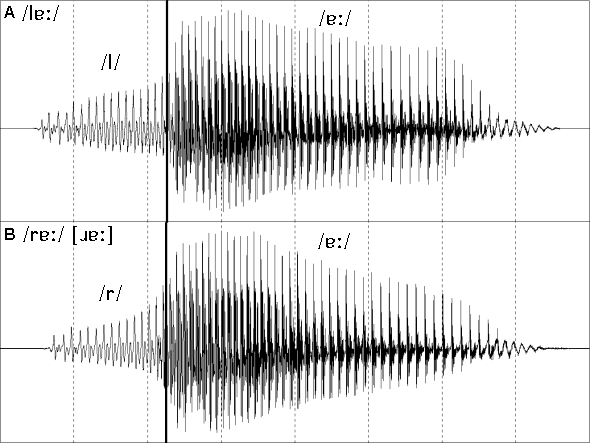
Figure 12: Waveforms of the English approximants /l/ and /r/ in CV context.
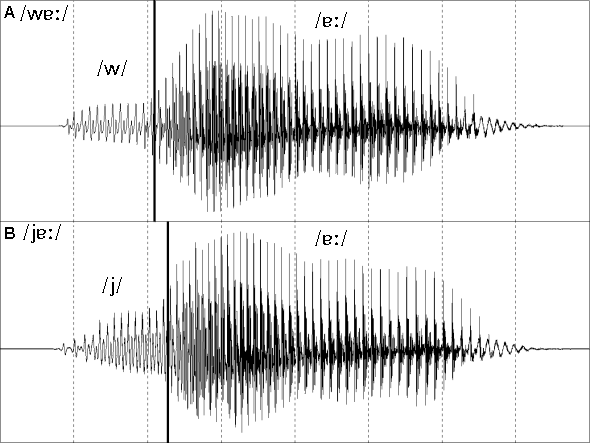
Figure 13: Waveforms of the two semi-vowels of English in CV context.
A close examination of figures 12 and 13 should convince you that there is no distinction in the appearance of the waveforms of the semi-vowels (2) /w/ and /j/ and the waveforms of the other approximants /l/ and /r/. For that matter, there is little that would allow us to distinguish between these four approximants and the nasal consonants in figure 11 from an examination of their waveforms. Whilst the nasal consonants most definitely belong to a separate phonetic class to the approximants, and the distinction is clearer when examining spectra and spectrograms (3), the nasals and the approximants could be said to belong to the same waveform visual class.
Waveform Visual Classes
For the purposes of this course we will define a number of "waveform visual classes". These classes are used purely for the practical purpose of distinguishing between pairs of waveforms. These waveform visual classes are not true phonetic classes, but they are sets consisting of one or more complete phonetic class. In the description below the waveform visual classes (WVC) are ranked in terms of the ease of their identification in contrast with other classes. Also, for the present, we will only consider consonant phonemes in simple CV syllables. In VC and VCV contexts the visual characteristics of some of the consonants can be quite different from their visual characteristics in CV context (this is particularly true for the oral stops).
a) The clearly separable consonant waveform visual classes:-
WVC#1: Strong Voiceless fricatives /s ʃ/: Gradually increasing aperiodic or random pattern, no bursts, relatively intense frication.
WVC#2: Weak Voiceless fricatives /f θ h/: Gradually increasing aperiodic or random pattern, no bursts, relatively weak frication.
WVC#3: Voiceless oral stops /p t k/: Aperiodic sound commencing abruptly with a burst.
WVC#4: Approximants and nasal consonants /l r w j m n ŋ/: Relatively simple periodic or voiced pattern and weaker in intensity than the vowel but rising smoothly to the vowel intensity over several glottal cycles during the consonant-vowel transition.
b) Ambiguous, difficult to distinguish consonant visual classes:
WVC#5: Affricates: Appearance intermediate between the stops and fricatives /tʃ dʒ/. /tʃ/ often looks like an intense stop, but sometimes its burst is not clear and so it will look more like a short voiceless fricative. /dʒ/ often looks quite similar to a voiced strong fricative /z ʒ/ but usually the aspiration phase is much stronger.
WVC#6: Voiced fricatives (strong and weak) /v ð z ʒ/: Can look a lot like WVC#4, but the mixture of periodicity and aperiodicity is sometimes clearly seen just before the vowel, especially for the strong fricatives /z ʒ/.
WVC#7: Voiced stops /b d ɡ/: When the burst is clear (especially for /d/) the identification of this class is possible but often the burst is unclear and these sounds look very much like voiced strong fricatives.
Footnotes
1. A nonsense syllable is a syllable which is not a real word in the target language.
2. Semi-vowels are treated as a sub-class of the approximants in this course.
3. See the topic on spectra and spectrograms for more information.
Content owner: Department of Linguistics Last updated: 23 Jun 2026 11:16am